

STAY TUNED
Learn more about DevOpsCon
The Beginning – Why was Kubernetes Created?
It also introduced new complexities in managing and orchestrating these distributed components. Deploying and maintaining a large number of services, each with its own lifecycle and dependencies, across multiple environments became a daunting task. The rise of microservices brought about numerous benefits, such as increased agility, scalability, and resilience. However, it also introduced new complexities in managing and orchestrating these distributed components. Deploying and maintaining a large number of services, each with its own lifecycle and dependencies, across multiple environments became a daunting task.
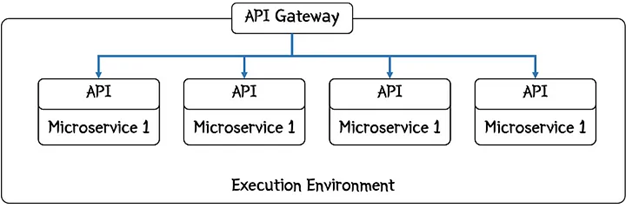
Figure 1: Micro services
Moreover, the advent of containerization, facilitated by technologies like Docker, introduced a new paradigm for packaging and deploying applications. Containers encapsulate an application and its dependencies, ensuring consistent behavior across different environments. However, managing and orchestrating large-scale containerized applications across multiple hosts posed significant challenges, including load balancing, scaling, self-healing, and service discovery.
In traditional deployment models, applications were often tightly coupled with the underlying infrastructure, making it difficult to achieve portability and scalability. Scaling an application typically involved provisioning additional hardware resources, which was a time-consuming and error-prone process. Furthermore, ensuring high availability and fault tolerance required complex manual intervention and scripting.

Figure 2: Too many micro services?
To address these challenges, engineers at Google set out to create a solution that would simplify the deployment, management, and scaling of containerized applications. Their efforts culminated in the development of Kubernetes, an open-source container orchestration platform that has since revolutionized the way applications are deployed and managed in the cloud and on-premises environments.
Here Comes Kubernetes – The Basic Idea of Kubernetes
Kubernetes, derived from the Greek word “κυβερνήτης” (kubernetes), meaning “helmsman” or “pilot,” is a powerful orchestration platform for managing containerized applications. Its primary goal is to abstract away the complexities of managing and scaling containerized workloads, allowing developers and operations teams to focus on building and delivering applications efficiently.
At its core, Kubernetes operates on a declarative model, where users define the desired state of their applications, and Kubernetes continuously works to reconcile the actual state with the desired state. This approach simplifies application management, as developers and operators no longer need to worry about low-level infrastructure details or manual scaling and deployment tasks.
Kubernetes achieves this by leveraging a set of core components and constructs, including Pods, Deployments, and Services, which work together to provide a comprehensive solution for deploying, managing, and scaling containerized applications.

Figure 3: Kubernetes to the rescue!
Wait! Containers? What are Containers?
Before diving into the core components of Kubernetes, it’s essential to understand containers, the building blocks of containerized applications. Containers are lightweight, standalone packages that encapsulate an application and its dependencies, including libraries, binaries, and configuration files. Unlike traditional virtual machines, which emulate entire operating systems, containers share the host machine’s kernel, resulting in efficient resource utilization and faster startup times.
Containers provide a consistent and reproducible environment for applications, ensuring that they behave identically across different environments, from development to production. This consistency eliminates the notorious “it works on my machine” problem and streamlines the development and deployment processes.
Containers are typically built using container images, which are lightweight, immutable filesystem snapshots that include everything needed to run an application. These images are then instantiated as containers on a host machine, providing an isolated and self-contained environment for the application to run.
One of the key benefits of containers is their portability. Since containers are self-contained and do not rely on specific underlying infrastructure, they can be easily moved between different environments, such as from a developer’s local machine to a staging or production environment, without requiring significant changes or configuration adjustments. Furthermore, containers promote a microservices architecture by allowing applications to be decomposed into smaller, modular components that can be packaged and deployed independently. This modular approach facilitates scalability, maintainability, and overall application flexibility.
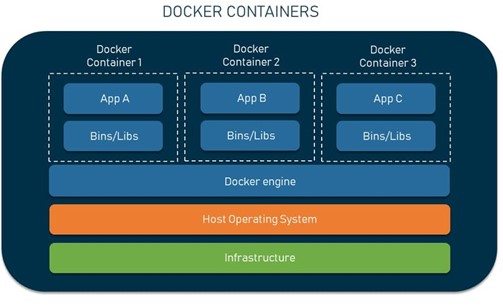
Figure 4: Docker containers
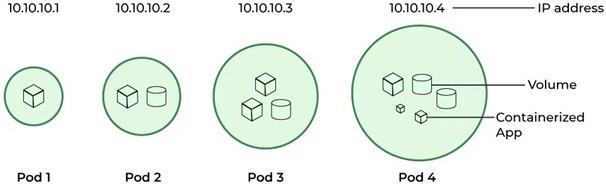
The Pod – What is a Pod and How is it Used?
In the world of Kubernetes, the fundamental unit of deployment is the Pod. A Pod is a group of one or more containers that share the same resources, such as network and storage. Pods are designed to be ephemeral, meaning they are created and destroyed as needed, and are not intended to be long-lived entities.
Pods serve several purposes in Kubernetes:
- Co-location: Pods allow multiple containers to be co-located on the same host, enabling them to share resources and communicate efficiently via localhost.
- Resource Sharing: Containers within a Pod share the same resources, such as storage volumes and IP addresses, facilitating seamless communication and data sharing.
- Management: Kubernetes manages Pods as a single entity, simplifying deployment, scaling, and failover mechanisms.
- Isolation: While containers within a Pod share resources, Pods themselves are isolated from other Pods, ensuring secure and efficient resource utilization.
When deploying an application in Kubernetes, users typically define one or more Pods that encapsulate the necessary containers for their application. These Pods are then scheduled to run on appropriate nodes (physical or virtual machines) within the Kubernetes cluster, based on resource requirements and other constraints defined by the user.
Here’s an example of a Pod definition in YAML format:
apiVersion: v1 kind: Pod metadata: name: example-pod spec: containers: name: container-1 image: nginx:latest ports: containerPort: 80 name: container-2 image: redis:latest
In this example, the Pod consists of two containers: one running the Nginx web server and another running the Redis in-memory data store. Both containers share the same resources within the Pod, such as the network namespace and storage volumes (if defined).
Pods can also specify resource requests and limits, allowing Kubernetes to manage and allocate resources effectively across the cluster. For example:
spec: containers: name: container-1 image: nginx:latest resources: requests: cpu: 100m memory: 128Mi limits: cpu: 500m memory: 256Mi
In this example, the container requests a minimum of 100 millicpu and 128 MiB of memory, while setting limits of 500 millicpu and 256 MiB to prevent resource starvation or excessive resource consumption. While Pods are the fundamental units of deployment, they are not intended to be directly managed by users. Instead, Kubernetes provides higher-level abstractions, such as Deployments, to manage and orchestrate Pods more effectively.
Use Cases for Running Multiple Containers in a Pod
Although Pods can consist of a single container, there are several use cases where running multiple containers within a single Pod can be beneficial:
- Sidecar Containers: Sidecar containers are auxiliary containers that extend or enhance the functionality of the main application For example, a sidecar container can be used to handle logging, monitoring, or proxying traffic for the main application container.
- Ambassador Containers: Ambassador containers act as proxies or gateways for other containers within the They can handle tasks such as SSL termination, authentication, or load balancing, offloading these responsibilities from the main application container.
- Adapter Containers: Adapter containers can be used to bridge the gap between different technologies or protocols. For example, an adapter container can translate requests from one protocol to another, enabling communication between components that do not natively support each other’s protocols.
- Initialization Containers: Initialization containers are specialized containers that run before the main application container starts. They can be used to perform setup tasks, such as initializing databases, copying files, or waiting for external services to become available.
- Tightly Coupled Components: In some cases, multiple components of an application may be tightly coupled and need to share resources or communicate efficiently. Running these components within the same Pod can improve performance and simplify communication.
- Shared Storage: When multiple containers within a Pod need to access the same persistent storage, running them within the same Pod can simplify storage management and reduce
- Resource Optimization: In certain scenarios, running multiple related containers within a single Pod can optimize resource utilization by sharing resources like CPU and memory.
It’s important to note that while running multiple containers in a Pod can offer benefits, it should be done judiciously. Tightly coupled containers within a Pod can introduce complications in terms of scalability, resilience, and maintainability. Therefore, it’s generally recommended to follow the principle of separating concerns and run each loosely coupled component in its own Pod whenever possible.
![]()
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Deployment – What is the Deployment Construct and What is it For?
While Pods are the fundamental units of deployment in Kubernetes, managing and scaling individual Pods can be cumbersome and error-prone. To address this challenge, Kubernetes introduces the concept of Deployments.
A Deployment is a higher-level abstraction that declaratively defines how Pods should be created, updated, and managed. It provides a convenient way to specify desired state for applications, including replicas, rolling updates, and rollbacks.
Key features of Deployments include:
- Replication and Scaling: Deployments allow users to specify the desired number of replicas (instances) of a Pod, ensuring high availability and fault tolerance. Kubernetes automatically manages the desired state, creating or terminating Pods as needed.
- Rolling Updates: Deployments enable seamless application updates by implementing rolling updates. During a rolling update, Kubernetes gradually replaces old Pods with new ones, ensuring zero downtime and minimizing disruption to users.
- Rollbacks: If an update introduces issues or regressions, Deployments allow for easy rollbacks to a previous stable version, providing a safety net for deployments.
- Self-healing: Kubernetes continuously monitors the health of Pods managed by a Deployment and automatically replaces failed or unhealthy Pods, ensuring application resilience and self-healing capabilities.
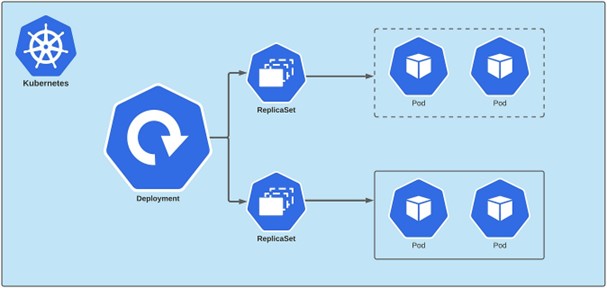
Figure 6: Kubernetes deployments
By leveraging Deployments, developers and operators can declaratively manage the lifecycle of their applications, ensuring consistent and reliable deployment processes, scaling, and updates.
Here’s an example of a Deployment definition in YAML format
apiVersion: apps/v1 kind: Deployment metadata: name: example-deployment spec: replicas: 3 selector: matchLabels: app: example-app template: metadata: labels: app: example-app spec: containers: - name: example-container image: example/app:v1 ports: - containerPort: 8080
In this example, the Deployment specifies that three replicas (instances) of the example-app Pod should be running. The `template` section defines the Pod specification, including the container image and ports. Kubernetes will continuously monitor and ensure that three replicas of this Pod are running at all times, automatically replacing any failed or unhealthy instances.
Deployments also support advanced update strategies, such as the `RollingUpdate` strategy, which allows for seamless application updates with zero downtime. During a rolling update, Kubernetes gradually terminates old Pods and creates new ones with the updated container image or configuration, ensuring that the desired number of replicas is always maintained. Additionally, Deployments maintain a revision history of their rolling updates, enabling easy rollbacks to a previous stable version in case of issues or regressions. This feature provides a safety net for deployments, reducing the risk associated with updates and enhancing application reliability. Deployments can be further customized through various configuration options, such as resource requests and limits, environment variables, and health checks. These configurations ensure that Pods are created and managed according to the specific requirements of the application, enabling efficient resource utilization and application health monitoring. Overall, Deployments simplify the management of Pods by providing a higher-level abstraction that handles replication, scaling, updates, and rollbacks, allowing developers and operators to focus on application development and delivery rather than low-level infrastructure management.
Service – What is the Service Construct and What is it For?
In a distributed system like Kubernetes, where Pods are ephemeral and can be replaced or rescheduled at any time, accessing individual Pods directly can be challenging and unreliable. To solve this issue, Kubernetes introduces the concept of Services. A Service is an abstraction that defines a logical set of Pods and provides a stable endpoint for accessing them. Services act as load balancers, distributing network traffic across the Pods that comprise the service.
Key features of Services include:
- Service Discovery: Services provide a stable DNS name and IP address that can be used by other components within the Kubernetes cluster to access the Pods associated with the service. This simplifies service discovery and improves application resilience.
- Load Balancing: Services automatically distribute incoming traffic across the Pods that make up the service, ensuring efficient load balancing and high availability.
- External Access: Services can be exposed externally, allowing external clients to access the application hosted in the Kubernetes cluster.
- Loose Coupling: Services decouple the frontend from the backend components, enabling more flexible and modular application architectures.
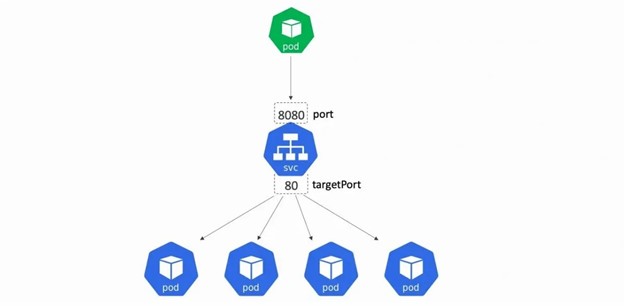
Figure 7: Kubernetes service
By leveraging Services, developers can create loosely coupled and highly available applications, while abstracting away the complexities of managing individual Pods and their network addresses.
Here’s an example of a Service definition in YAML format:
apiVersion: v1 kind: Service metadata: name: example-service spec: selector: app: example-app ports: - port: 80 targetPort: 8080
In this example, the Service selects Pods with the label `app=example-app` and exposes them on port 80. Incoming traffic on port 80 is load-balanced across all the Pods matching the selector. The `targetPort` specifies the container port (8080) where the application is listening.
Services can be of different types, depending on the desired access pattern:
- ClusterIP (default): Exposes the service on an internal IP address within the cluster. This type is suitable for internal communication between components within the Kubernetes
- NodePort: Exposes the service on the same port on each node in the cluster, allowing external clients to access the service via the node’s IP address and the specified port.
- LoadBalancer: Provisions an external load balancer and assigns an external IP address to the service, enabling external clients to access the service via the load balancer’s IP
By choosing the appropriate Service type, developers can control the accessibility and exposure of their applications, either internally within the cluster or externally to the outside world.
In addition to load balancing and service discovery, Services also provide a way to abstract away the underlying network infrastructure, enabling seamless communication between components. For example, if a Pod is rescheduled to a different node due to node failure or scaling events, the Service automatically adjusts its routing to ensure that traffic is directed to the new Pod’s IP address, without requiring any changes to the client applications. Services can also be configured with additional options, such as session affinity and external IP addresses, allowing for more advanced traffic management and exposure scenarios.
Overall, Services play a crucial role in Kubernetes by providing a stable and reliable way to access and communicate with Pods, while abstracting away the complexities of network infrastructure and Pod lifecycles.
Bring it All Together – How are All the Above Constructs Work Together?
Now that we’ve explored the individual components of Kubernetes, let’s see how they work together to enable efficient application deployment, management, and scaling.
- Packaging: Developers package their application components as Docker containers, encapsulating all the necessary dependencies and configurations.
- Defining Pods: The containerized components are grouped into one or more Pods, specifying their resource requirements, environmental variables, and other
- Creating Deployments: Developers define Deployments that specify the desired state of their application, including the number of replicas, update strategies, and rollback
- Scheduling and Orchestration: Kubernetes schedules the Pods specified in the Deployments across the available nodes in the cluster, considering resource constraints, node affinity, and other factors.
- Service Creation: Developers create Services that provide stable endpoints and load balancing capabilities for the Pods associated with their application.
- External Access: If required, Services can be exposed externally, allowing external clients to access the application hosted in the Kubernetes cluster.
- Monitoring and Self-Healing: Kubernetes continuously monitors the health of Pods and automatically replaces failed or unhealthy instances, ensuring application resilience and self-healing capabilities.
- Scaling and Updates: As application demands change, developers can scale their Deployments by adjusting the desired number of Rolling updates can be performed seamlessly, ensuring zero downtime and minimizing disruption to users.
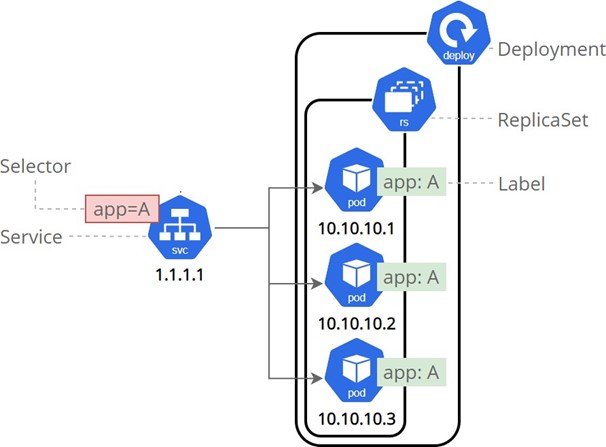
Figure 8: Running Kubernetes service, deployment and pods – a micro service is born!

Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
By combining Pods, Deployments, and Services, Kubernetes provides a comprehensive solution for deploying, managing, and scaling containerized applications. This powerful orchestration platform enables developers and operators to focus on building and delivering applications, while Kubernetes handles the complexities of infrastructure management, resource allocation, and application lifecycle management. There are many other Kubernetes constructs, like Volumes, Ingress controllers and others, but I’ll discuss them in another article. In the meantime, you have all the knowledge to run your own set of micro services – in Kubernetes!







